I have weaponized my Autism to do a whole bunch of really cool things… none of which I actually need. Hopefully, if I talk about it on here, I can feel some more justification for my irresponsible actions.
Manual Integration, Manual Deployment
The main snagging point I ran into when moving my self-host infrastructure from pm2 opens in a new tab to Docker Compose opens in a new tab is that deploying a new version of my website became much more convoluted.
This is what my deployment workflow looked like before:
- ssh into my VPS
cdto the copy of the git repo in my home directory andgit pullmy new changes from forgejo opens in a new tab- rebuild the website with
pnpm build - restart the website’s node server with
pm2 restart 0
And this is what the deployment workflow looks like now:
- ssh into my VPS
cdto the copy of the git repo in my home diretory andgit pullmy new changes from forgejo- build the new image of my website with
docker build <repo directory> -t git.eleboog.com/kebokyo/eleboog-astro:latest - log into my forgejo’s container registry with
docker login git.eleboog.com - upload the new website image to my forgejo with
docker push git.eleboog.com/kebokyo/eleboog-astro:latest - restart the website’s container with the new image by
6a. firstcd-ing into thecomposedirectory where my Docker Compose configuration lives, and
6b. then runningdocker compose up --force-recreate eleboogto make the container restart and grab the new image from forgejo
Yeah. That’s a lot more painful. I’m sure the actual developers in the chat would be upset at me still having a copy of the repo in my home directory and would rather me be using a CI/CD system like Woodpecker opens in a new tab or even Forgejo’s own Actions system opens in a new tab , but here’s the thing: I’ve already tried those. They don’t work. (or at least, I can’t figure out how to get them to work lol)
So, instead, I decided to make a shell script that automates everything for me. I found a little script on StackOverflow opens in a new tab that lets you check whether you need to pull or push your local git repo from/to your remote repo, and used that as the basis of my script to determine whether there are updates available that need to be integrated and deployed.
Here’s the entire script for anyone who wants to try a similar thing with their own setup (with certain variables omitted for paranoia reasons lol):
#!/bin/sh
$REPO=<hehehe>
$COMPOSE=<hohohohoho>
$TAG="git.eleboog.com/kebokyo/eleboog-astro:latest"
LOCAL=$(git -C "$REPO" rev-parse @)
REMOTE=$(git -C "$REPO" rev-parse "@{u}")
BASE=$(git -C "$REPO" merge-base @ "@{u}")
if [ "$1" = "-f" ]; then
echo "Forcing update..."
# continue
elif [ "$LOCAL" = "$REMOTE" ]; then
echo "No need for update; exiting"
exit
elif [ "$LOCAL" = "$BASE" ]; then
echo "Update started..."
# continue
elif [ "$REMOTE" = "$BASE" ]; then
echo "Need to push current changes; exiting" 1>&2
exit
else
echo "Diverged paths; exiting" 1>&2
exit
fi
git -C "$REPO" pull
docker login git.eleboog.com
docker build "$REPO" -t "$TAG"
docker push "$TAG"
docker compose -f "$COMPOSE" up --force-recreate -d eleboog
docker image prune -f
echo "Update succeeded!"
Now, all I need to do is ssh into my server with the autorun command pointed to this script, and I can automatically deploy my website changes lickity-split! I’m very proud of myself for this, please give me $100.
Trans Girl Twitter
I also decided to make an Akkoma instance for myself on my second VPS! That way, I can easily make automated posts on new blog posts and journal entires without having to rely on another person’s instance playing nice with me. It also gives me an alternative if plush.city opens in a new tab , my current fedi instance, ever decides to do something stupid.
You can currently find it on ak.eleboog.com opens in a new tab , tho it’s absolutely nothing much right now. I still need to fix image storage lmao. My account on there can be found with the same @kebokyo username.
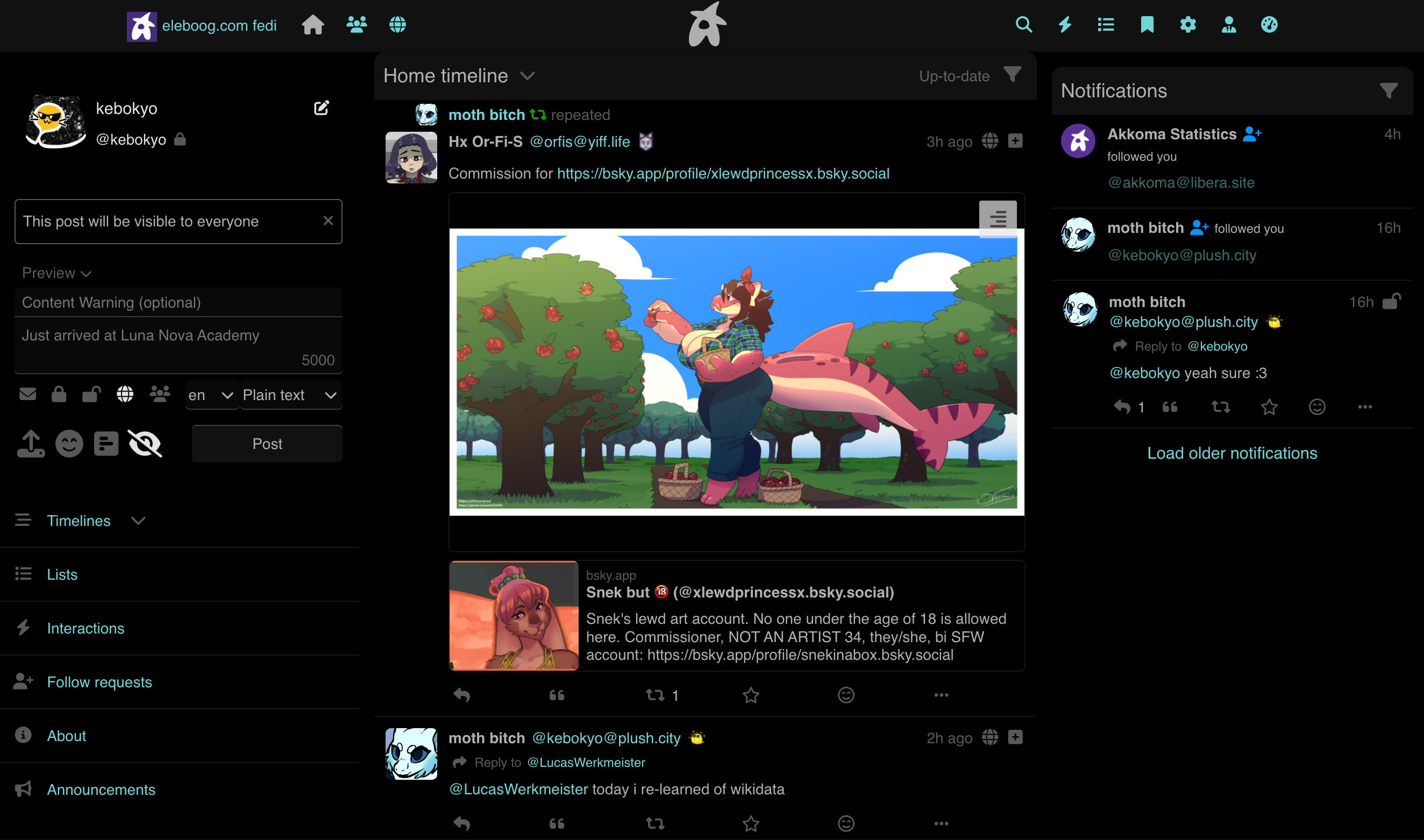
A screenshot of my Akkoma instance's home screen, showing multiple posts & reposts from my main fediverse account as well as the three-column layout of the default frontend.
I’m a Real Programmer Now
I have finally decided to get into Neovim opens in a new tab , specifically for editing my blog. VSCode is still waaayyyy to heavy for me, and I would rather use something simpler and cleaner for writing blog posts.
I was inspired to do this by BreadOnPenguins’s video opens in a new tab on their Neovim setup: it looked straightforward, well-structured, and a great place to start for my own setup. So, I stole it! No one will ever know!!!1! opens in a new tab >:3
…well, I stole most of it; I left out certain plugins like the integrated terminal and tweaked some of the settings to work better for me. I also made .mdx files
register to Neovim as Markdown files so all of the fancy Markdown plugins like render-markdown opens in a new tab would work with my MDX opens in a new tab workflow.
The main plugins I have installed are:
- lualine opens in a new tab for a rich lower status bar
- barbar opens in a new tab for a visual tab bar
- which-key opens in a new tab for a keybind atlas & autocomplete support
- treesitter opens in a new tab for better syntax highlighting support
- nvim-tree opens in a new tab to add a file explorer side panel to Neovim
- nvim-web-devicons opens in a new tab to allow Neovim plugins to use Nerd Font icons
- render-markdown opens in a new tab to automatically render Markdown rich text
- fsf-lua opens in a new tab for fuzzy searching support
All of this combines together to form a minimalist yet richly featured code editor that makes VSCode piss its pants.
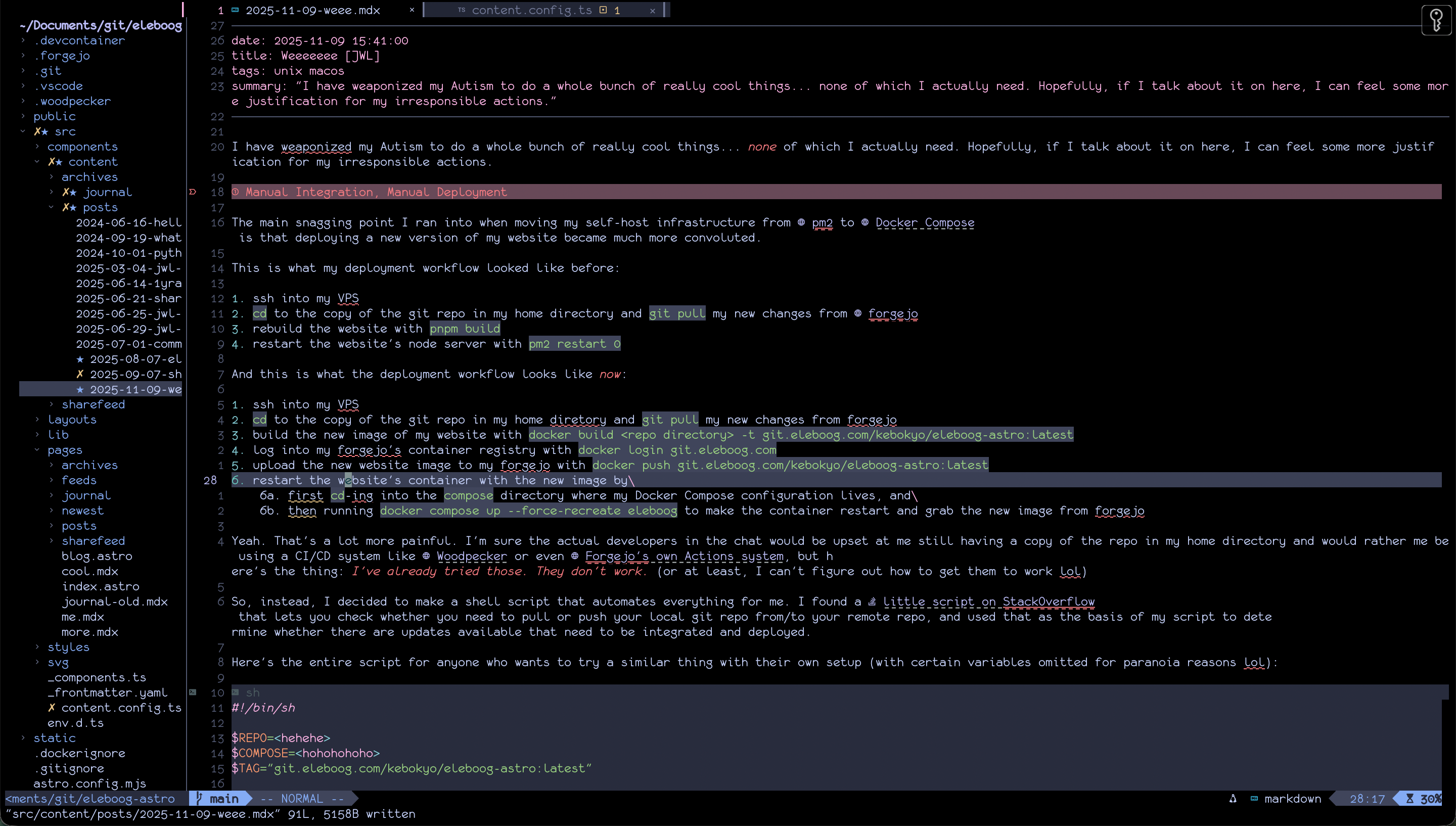
A screenshot of this very blog post being made in Neovim, complete with file tree, tab management, git status, and automatic Markdown rendering.
You can find my Neovim config files as a git repo on my forgejo opens in a new tab . I also made this a repo for myself: once I get back on my desktop PC, it would be nice to grab my config from my forgejo and have everything set up the way I like it! This is why I also plan to publish my dotfiles on my forgejo once I get them more finalized and organized.
(oh, and I also made an iTerm2 hotkey where ⌘+s sends <Esc>l:wi to the terminal so I can stop pressing it and then feeling stupid that it doesn’t do anything lmfao)
Conclusion
ADHD is a bitch, but it’s okay when it allows you to hyperfocus on a bunch of seemingly-unrelated things that make you feel really good about yourself and your ability to manifest into reality your wildest dreams.
But now I really gotta get back to work. See y’all.