
warning
This post has not been fully proofread yet. I just wanted to get this out there because I am tired of only having one blog post on my site.
Last week, I did a lab for my intro to physics course. This was the first experimental lab, and so I had to learn how to work a piece of software named Vernier LoggerPro opens in a new tab . Since we use Vernier sensors for all of our data collection, we use Vernier’s LoggerPro software to actually record the data.
The lab manual for this particular lab specifically stated that we needed to log all of the data we collected for nine different trials in a document made using Google’s Colab service opens in a new tab . Colab (one ‘l’, not two) is a cloud-based webapp that allows you to make Jupyter-compatible Python notebooks online and store those notebooks in your Google Drive. In non-tech speak, it lets you write blocks of Python code, run those blocks of code individually so you can immediately see the results of that code, and insert rich text inbetween those blocks of code so you can give further context as to what you are doing.
When you copy data from LoggerPro into a Colab document, you end up with a blob of text formatted as a vertically-oriented table. Each column represents a different type of data (in my case: time, position, & velocity), and each row represents a specific sample of data (like, in my case, the position & velocity of an object 0.5 seconds after the start data collection).
0.85 0.1932805 0.446948055556
0.9 0.227066 0.668087777778
0.95 0.265139 0.786518055556
1 0.3068135 0.867027777778
1.05 0.3517465 0.940296388889
1.1 0.4007955 1.01394611111
1.15 0.4532745 1.085595
1.2 0.509355 1.15772027778
1.25 0.5688655 1.23432361111
1.3 0.632492 1.32293194444
1.35 0.7002345 1.41468444444
1.4 0.773465 1.46260916667
1.45 0.859901 1.2219375
1.5 0.9139235 0.638075277778
To use this data in graphing libraries such as Matplotlib opens in a new tab , I need to convert this data into a set of arrays, or “lists” as they are called in Python. Problem: Matplotlib wants each type of data to be in its own list… which means I need to rotate this graph 90° (or, as the math kids call it, “transpose” the table).
I’ve talked to other students who took this class about it, and their solutions were something like this:
- Make an Excel spreadsheet.
- Put the data in that spreadsheet.
- Use Excel’s transpose tool to rotate the table.
- Export the spreadsheet as a CSV file or just leave it as is.
- Upload the spreadsheet to Google Drive and read it using file management functions, either by Google or by a third-party library.
I originally did the same… but I put the data into a code editor first… and then I converted it into a CSV… and then I imported the CSV into Excel… and then I translated the graph… and then I copy and pasted the text into Colab to manually convert into lists…
Obviously, all of this was incredibly tedious and convoluted and absolutely not the right way to do any of this. There’s got to be a better way!!1!1!!!!
So, I made a function in Python to do all of this for me. It’s actually way simpler than I thought it would be and I feel incredibly dumb both for myself and everyone else who tried to rope Excel into being the solution.
I’m going to be annoying and not show you the actual function until the very end of this post. However, I will be more than happy to walk you through how I wrote it!
How I Did the Thing
This function does not require any third-party libraries or even any standard libraries/modules. All you need is some basic knowledge of Python and a healthy software engineering spirit.
Also, quick disclaimer: I am assuming that you are like my fellow physics students — not good at Python or programming in general. Thus, I will overexplain a lot of stuff so that I can help make you somewhat good at Python. If you are already fluent in programming mumbo-jumbo, I will kindly suggest to just skip to the end of this article (the table of contents can take you right there) and just look up the parts of the code that you don’t understand. If you know other programming languages but don’t know Python and you’re still just getting started with this whole “programming” thing, I still recommend you read through the whole article just to get familiar with Python and its quirks and features opens in a new tab .
At the beginining
We start off by defining the variable we will use to store our new set of lists:
out = []
It is given the name “out” because it is the “output” of the function. Get it? Eh? Eh????
I initialize this variable by making the variable equal to an empty list. If I wanted to put stuff in the list from the getgo, I could put
numbers or values inbetween the square brackets (so, doing out = [1, 2, 3] would make out a list with three numbers: 1, 2, & 3).
But I don’t want to do that here because I don’t actually know how much stuff we’re actually going to put in here. All I want to do is
establish that out is a list for use later when we actually start filling it up. Thus, I make it equal to an empty list with nothing
inbetween the brackets.
In my actual function, I put a type hint on this variable so that it’s obvious what’s supposed to go in it. You don’t have to do this,
but I think it’s a good idea regardless. For this variable, it will be a list containing lists of floating point numbers (yes, I know,
Listception, get your bwwaaaahhh opens in a new tab ’s out now cause I’m not allowing you to do it again).
So, the type hint for this variable should be list[list[float]].
out: list[list[float]] = []
In most other programming languages, we would call this list of lists a “two-dimensional array”, or “2D array” for short. I’m going to be using that term interchangably with “table” from now on — just wanted to let you know so I don’t confuse you.
But how do we put stuff in this variable? That’s what the rest of this function is for: to parse through the blob of text from LoggerPro
and store it as our desired transposed 2D array in the out variable.
We need to solve a small problem first: how do we store our raw LoggerPro dump? Luckily, Python lets us define a string with multiple lines in it pretty easily: just flank the text with three quote marks (single or double, doesn’t matter as long as both ends match).
test_dump = '''0.85 0.1932805 0.446948055556
0.9 0.227066 0.668087777778
0.95 0.265139 0.786518055556
1 0.3068135 0.867027777778
1.05 0.3517465 0.940296388889
1.1 0.4007955 1.01394611111
1.15 0.4532745 1.085595
1.2 0.509355 1.15772027778
1.25 0.5688655 1.23432361111
1.3 0.632492 1.32293194444
1.35 0.7002345 1.41468444444
1.4 0.773465 1.46260916667
1.45 0.859901 1.2219375
1.5 0.9139235 0.638075277778'''
We’re doing it this way because Python has built-in functions for iterating over multi-line strings pretty easily. I’ll show you what they are later. Plus, it’s the easiest way (imo) to go from raw dump to usable input: just add a variable name, an equals sign, and three quote marks around the data. Boom. Shrimple.
Now that we’ve got our data stored in a way that’s easily parsable, all we need to do is feed it into our function as an argument.
I decided to add type hints to the top of the function so it is super duper obvious what we’re putting into it and what we’re getting
out of it. We’re feeding the function a single string (which has the type name str for some reason) and getting back our 2D array of
floating-point numbers (type name float) that we defined at the top of the function. So, the header line for the function would look
something like this:
def LoggerProToArray(text: str) -> list[list[float]]:
Again, we don’t have to do fancy type hinting like this. We could just do…
def LoggerProToArray(text):
and that’s it. The function will still work the same.
The type hints are only there to make it obvious what types of data we are working with and should expect. Sadly, Google Colab doesn’t do type checking with its interpreter, but other apps that let you write Python code may have support for “linting” utilities that take type hints into account and yell at you if you’re passing in conflicting types of data. I won’t go into how they work here, but if you really want to know, I suggest you look it up.
Let’s start parsing!
First, let’s take our text and divide it up by its lines. To do this, we can just slap .splitlines() at the end of our input variable.
lines: list[str] = text.splitlines()
This will take our single string and split it up into a list of strings, where each line becomes its own entry in the list. That’s pretty easy, right?
We also want to keep track of whether we are currently reading the first line of our data or not. Why? I’ll get to that soon.
I used to do this by keeping track of the line number through a function we’re going to learn about later (enumerate()) but I
realized that was dumb if I only want to focus on the very first line. So, I made a boolean for it.
first: bool = True
If you don’t know already, a “boolean” (type name bool in Python) is a value that is either true or false. On or off. 1 or 0. Yes or no.
Here, we set our variable to True since, when we start iterating through our lines, the first line we read… will be the first line
of the data. Duh.
Note that the ‘T’ in True is capitalized. This is a quirk of Python compared to other languages: the names for the base values of
“true” and “false” are capitalized. So, if you want to define a boolean to be true, you can’t use var = true — you have to use
var = True. I learned that the hard way. Whoops.
Alternatively, you could just say screw it and use numbers instead:
first: bool = 1
Remember that third example I gave? “1 or 0”? That works here. 1 is always read as equivalent to True (in other words, it is a “truthy”
value). On the other hand, 0 is always read as equivalent to False (in other words, it is a “falsy” value). So, whenever you need to use
True and False, you can use 1 and 0 respectively. This is very helpful if you are allergic to capital letters.
I don’t do this in my function as I feel like True and False are easier to read from an outside persepctive, but for your own code, it
doesn’t really matter as long as you understand it and it gets the job done.
Anyways, now it’s time to go through the text line-by-line. To do this, we can use what is called a for loop.
for line in lines:
There are two main types of “for” loops in programming. There’s the one you mostly see in C, C++, and other languages like it with
i=0; i>n; i++ or something like that, but that’s not what we’re doing here.
This version lets us loop through a list of values and do something with each value in the list. This is what is usually called an
“iterator-based” for loop and is also included in some languages with the keyword foreach instead of for.
So, for each line contained in our list of lines, we need to parse that line and plop the data within it into our output array.
How do we do that? WE SPLIT IT AGAIN, HAHAHAHAHA
But this time, we can’t just use .splitlines() because the data within each line isn’t separated by a line break. We know what each
value is separated by, though…
Scroll back up to the raw dump as pasted from LoggerPro. Try highlighting the space inbetween each value. Notice how the highlight can’t end halfway inside the whitespace — it always highlights the full amount of space present.
The reason why is because each value is separated from the others by a “tab” character, i.e. the whitespace character that (should) come out when you press the “tab” key on your keyboard. If they were separated by space characters (the whitespace character that comes out when you press the spacebar), you would be able to select only part of the space inbetween values since it would usually take multiple space characters to fill up the space taken up by a tab.
Tab characters can change in size so that it is easier to vertically orient text. Space characters are always the same size.
Here’s a little example to show you the difference:
This sentence is broken up by a tab.
This sentence is broken up by spaces.
Try highlighting only part of the space that breaks up both sentences. In the first sentence, you can’t because all of that space is being taken up by a single tab character. In the second sentence. you can because that space is being filled with multiple space characters. In this instance, it takes four space characters to fill the same space that a single tab character can.
What if we changed the actual text of both sentences?
This sentence isn't broken up by a tab.
This sentence isn't broken up by spaces... wait a second...
Look at that magic! In both of these scenarios, I converted is into isn't by adding the n't to the end of is in each sentence.
In the sentence with a tab, the tab shrunk automatically to keep the second half of the sentence in the same place.
Now, the tab character taking up the equivalent of a single space character.
On the other hand, when I did the same thing to the sentence with space characters, all of the spaces were moved to the right, misaligning the second part of the sentence. There are still four spaces, taking up the same amount of space as it did the first time.
I know all of this sounds dumb (and it kinda is; it’s so dumb that there is an entire nerd war over it opens in a new tab ), but it is actually significant in this case because of the fact that there is only one (1) tab character inbetween each value. Feel free to check for yourself again: every time you highlight between the data values, you only highlight the entire width of the space because that space is only being taken up by one character.
What can we do with that infomation? Well, all we need to do to split each line into its own list of values is to do this:
split: list[str] = line.split("\t")
This is just like .splitlines() from earlier, but instead of splitting the string using line returns, it splits the string by looking for
whatever character or other string we want. In our case, we want this function to look for tab characters, so we use the shorthand code
\t to tell the function that we want to look for tab characters.
When it does split up the string, all of the values within the table will be perfectly contained without any whitespace around it. Why? The only whitespace that exists per line of data are the tab characters that go between each value… and since there’s only one of them per pair of values, we already got rid of it when we did the split!
Thus, we have ended up with another list of strings that we are again going to iterate through to do what we want. Yay.
The Home Stretch
First, we need to check if we are on the first line of data. We can check this very easily:
if (first):
This is a neat shorthand for if (first == True). If our first boolean is true, then we will execute the code indented under this
if statement. What are we going to do? Another for loop!
if (first):
for e in split:
out.append( [float(e)] )
first = False
Let’s break this down real quick:
- We want to iterate through our list of values. This time, I got lazy and named our iterator variable
e, short for “entry”. - Our
outtable was previously defined as just an empty list ([]). I didn’t want to define how many lists are inside it, just in case our input had a different amount of columns than the three that we had in our example data. So, to start off inserting our data into ourouttable, we need to first create new lists within the table. To do this, we can simply.append()a new list to the end of ourouttable containing just one element… - That element is
e… in a function namedfloat(). Wait, what are we doing here?
We could just put e inside this list and call it a day, but if we do that, we will be storing text inside our array, not a number.
Why? We started off by storing our
data as a big string, so even though we’ve gradually whittled down that big block of text into the individual values… it’s still being stored
as text right now.
This may not seem like a big deal, but in my original version of the function, I ran into issues working with my data because certain library functions were expecting a list of numbers when I was actually giving it a list of strings. This is the one instance in which knowing what type a variable is or contains is actually important in this function.
So, to fix that, I can use a built-in cheat code: just wrap e in a function named after the type
I want to convert e into — in this case, a float. This function will parse the string e, see that the text inside the string is
indeed a floating point number, and give us that floating point number as an actual number of type float. That number is exactly what
we want: the values within out need to be actual numbers we can do actual math with, not the text representing those values within our
input string.
Anyways, to wrap up: after we have parsed our entire list of values, we want to make sure we know we are moving on to a new line that isn’t
the first line. If we didn’t, we would just add new one-member lists to the end of out over and over again!! So, at the end of the if
statement, we need to set our first boolean to False.
One very important thing to note here: our last line for this chunk of code is one indent behind the code we are executing in the for
loop. Python is dumb and actually cares about indents. If you use something like an if, for, or def statement, you must indent all of
the code that is meant to be executed under that statement. If you’re not sure whether you need to indent, check to see if the line ends in a colon.
If a line of code ends in a colon, the following code that you want to run under the conditions of that line likely needs to be indented.
If that code isn’t indented far enough, the Python interpreter won’t recognize that the code
should be executed under that if, for, or def statement, so it won’t run that code under those parameters.
So, wait… why are we intentionally not indenting that last line enough? Well, it’s simple: that line of code shouldn’t be executed
after every run of our for loop. If it was indented all the way, that line of code would run after each value is processed instead of
after we’ve processed all of the values. It wouldn’t change anything if that happened in this specific instance, but since we only need to
update this boolean once,
it’s probably a good idea to make sure it only updates once.
By moving this line of code back an indent, we are telling the interpreter that we only want the code to run under the conditions of our
if statement and our def statement, not under the conditions of our for statement.
This idea of code only being ran under a particular set of parameters is called “scope”, and it is a very important concept in programming. I suggest that you look up more information about it and how it specifically applies to Python, as mishandling scope is a very easy way for your code to completely fall apart if you do not watch out for it.
To the CS students in the audience, I know that this should be bare basic knowledge, but the fact that indents actually matter is a quirk of Python that still trips me up sometimes and likely will trip you up as well. Most other programming languages don’t care: Python does. That distinction is important to keep in mind.
Now that we know what to do if first is true… What if it’s false? Like, after we run that first bit of code that
sets first to False at the end… What do we do after that?
We can easily define what to do in that case by putting else: after our if statement’s code:
else:
The else statement only executes if the condition given to the previous if statement is not true. So, if our first boolean is found
to be true, the code directly under the if statement is ran. However, if our first boolean is found to be false, then we run the code
under else. You can think of it like “If this is true, do this… or else, do this instead.”
So, what else are we cooking?
else:
for i, e in enumerate(split):
out[i].append(float(e))
Hey, there’s that enumerate() function I talked about earlier! If we give a for statement a list wrapped in this function, we will
get two variables to work with instead of one: our single value variable e and the “index” of that value in the list, which I have
shortened to i.
The “index” is the number given to our value’s “place” within the order of the list. In Python and most other programming languages
(except for the bad ones /j), lists start at an index of 0. This means that the first entry of a list will always be given the index 0.
That may seem dumb at first, but it is actually really handy when you start working with the other type of for loops and other
programming tasks like it. I won’t get into why here, but if you’re curious, say it with me: “Look it up!” That’s right.
So, let’s say we wanted to get the first element of our list split. To do that, all we need to do is call it as split[0]. The number in
the square brackets tells Python to look through the list and grab the element at that index number. Since the number this time is 0, we will
grab the element at index 0… the first one!
The last line of this chunk of code utilizes our i variable to determine which of our new rows within out we should put this value
into. Remember that out is now a list containing other lists. In the case of Python, the outer list represents the rows of our table,
while the individual values within that row represent the columns of our table. So, if we wanted to get the second row of out,
all we need to do is call out[2]. That will give us a list of all of the values in row 2. If we wanted to grab just the third element of that
row, we can call out[2][3]. Since out[2] is itself a list, we can just slap another number in square brackets at the end of it to grab an
element within that list. I know. I know you really want to do it. I know you really want to say it. But I gave you that one chance. I am not
giving you another one. Weep.
We can use the fact that out is a list of lists to our advantage. Also remember that we want the columns of our old table to become
the rows of our new table. In our old table, each row represented a particular set of data, and each column represented a type of data.
We want things to be the opposite: the rows should contain individual types of data, and the columns should contain individual samples of data.
The easiest way to make this happen is to switch the indexes of our new table around. So, when we are iterating by columns through
our old table, the index of that column will become the index of the new row we want to insert our value into. That is why we are
using enumerate() here: As we go through each value, we are given the index of that value within our old table’s columns. All we
need to do to translate our old table’s columns into our new table’s rows… is to just use that fancy shmancy index we got to specify
which row of out to insert our data into.
For example, if we are on the second value on this particular line of data, when we add it to out, we want to add it to the second row
of out. To do that, we can .append() our value to the end of the second list contained within out — in other words:
out[1].append(value)
Rember that since list indexes start from 0, to get the second row of out, we need to use index 1. An easy way to keep track of what
index number to use is to just subtract the numbered version of your place by one. The 1st row minus one gives you 0. The 2nd row minus one
gives you 1, so that’s the index number we need to use.
Of course, we still don’t know how many columns of values we will get in our original data table, so instead of hard-coding each of those
index numbers, we will just use our index variable i, since we know i will represent the index of our data value within our current
for loop.
Oh, and again, we want the value we slot in to be an actual number, not text, so we’re converting it into a float first with float().
We did it!
We are on. The last line. Of our function. We came a long way. But now it is time to finish this.
At the end of the function, with only one indent (since we’re only under our function’s def statement from the very top now), we
need to send out the two-dimensional array we made. To do that, we only need two words:
return out
This will make our function “return” our variable out when it is ran without issues up to this point. If you were to just call this
function by itself, without anything else around it, you could get out printed to the standard output.
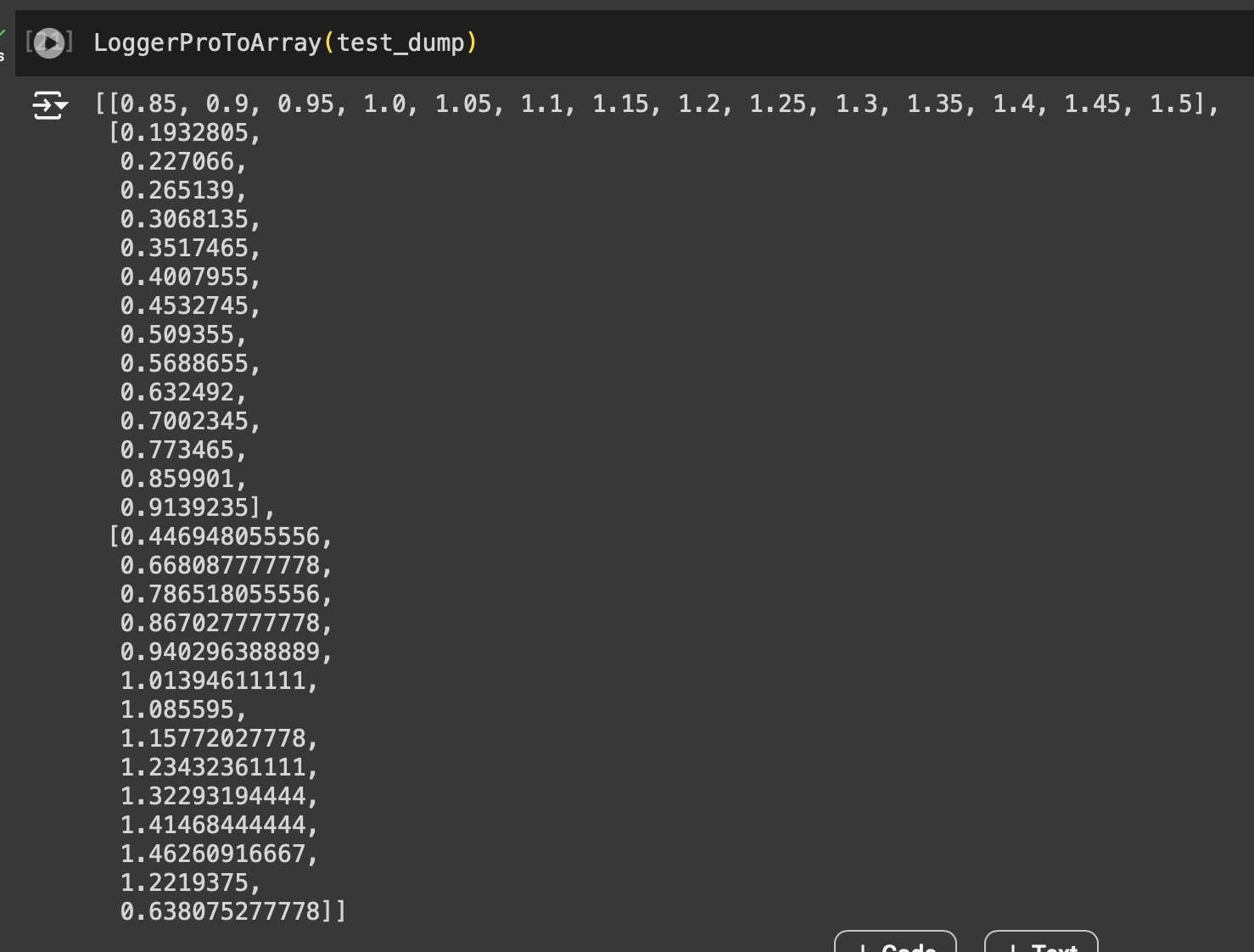
A screenshot showing the output of LoggerProToArray when ran by itself in Google Colab.
You can also store the output into a variable:
test_output = LoggerProToArray(test_dump)
Now the data within the out array we were working with inside our function is stored within our new variable, test_output. And we
didn’t have to write all of that code again! Yay for reduced redundancy!!!
Hopefully this ramble helped you learn some stuff about coding in Python. I encourage you to try writing this code yourself, step by step, using this article as a guide. Don’t copy and paste each line from my code examples; write it by hand. It helps you absorb the information better. I would cite a study here about it but it’s midnight and I’m tired and I want to go to beb.
If you would rather just grab the entire function and use it in your own code…
The thing you actually came here for
Ok fine, here’s the code you want. All I ask is that if you use this anywhere, leave a link to either me or this particular webpage in a comment above this. If you are a student like me, I do not want you to get in trouble for using code that you did not write.
def LoggerProToArray(text: str) -> list[list[float]]:
'''Converts a Logger Pro dump into a 2D array / table of values,
translated for use in graphing.
Written by kebokyo - https://eleboog.com/posts/2024-10-01-python-lab
Args
------
text : str
The Logger Pro dump imported as a multiline string.
Returns
----------
list[list[float]]
A two-dimensional array that contains lists of floats.
'''
out: list[list[float]] = [] # The 2D array we are returning
lines: list[str] = text.splitlines() # Let's split our text into lines
first: bool = True # & keep track of whether we're on the first line or not
line: str
for line in lines: # Time to go through the text line by line!
split: list[str] = line.split("\t") # First, split each line by tab-delimitated values
if (first): # If we're on the first row...
for e in split: # For each value in this row,
out.append([float(e)]) # Make a new array for each *new* row
first = False # When we're done, make sure we know we're done w/ the first line
else:
for i, e in enumerate(split): # For all other rows...
out[i].append(float(e)) # Append the values to each new row
return out # Then just return the new array!
Oh, and in case you’re curious, I found the footage for the silly green screen explosion here opens in a new tab .